隨著信息技術的迅猛發展,人們獲取新聞資訊的方式從傳統媒體轉向了數字化平臺。信息過載問題日益凸顯,用戶難以從海量新聞中快速找到自己感興趣的內容。個性化推薦系統應運而生,成為解決這一問題的關鍵技術。本文旨在探討一個基于SpringBoot框架,采用協同過濾算法實現的新聞推薦系統(項目參考編號:9k0339),該系統旨在為計算機系統服務領域提供一個高效、可擴展的個性化新聞推薦解決方案。
1. 系統概述與背景
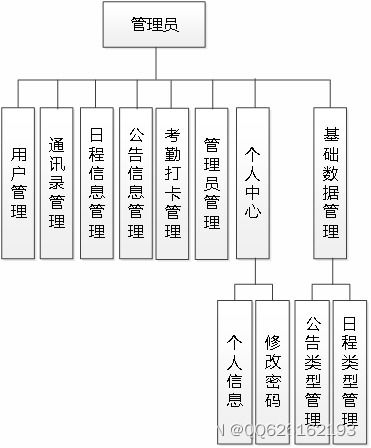
本系統被歸類為“計算機系統服務”,核心目標是構建一個智能化的新聞分發平臺。通過分析用戶的歷史瀏覽記錄、點擊行為及評分數據,系統能夠自動學習用戶的興趣偏好,并為其推薦可能感興趣的新聞文章,從而提升用戶體驗和信息獲取效率。SpringBoot框架因其簡化配置、快速開發、微服務友好等特性,被選為系統后端開發的基礎,確保了系統的高效構建與穩定運行。
2. 核心技術:協同過濾算法
協同過濾是本推薦系統的核心算法。它主要分為兩類:
- 基于用戶的協同過濾:通過尋找與目標用戶興趣相似的其他用戶,將這些相似用戶喜歡而目標用戶未瀏覽過的新聞推薦給目標用戶。其關鍵在于計算用戶之間的相似度(如余弦相似度或皮爾遜相關系數)。
- 基于物品的協同過濾:通過分析新聞文章之間的相似性(例如,被同一批用戶點擊或喜歡),將與用戶歷史喜好新聞相似的其他新聞推薦給用戶。這種方法通常更穩定,因為新聞間的相似性比用戶興趣的變化更緩慢。
本系統計劃結合兩種方法的優勢,并采用矩陣分解等優化技術來處理數據稀疏性和冷啟動問題,提高推薦的準確性和覆蓋率。
3. 系統架構設計與模塊劃分
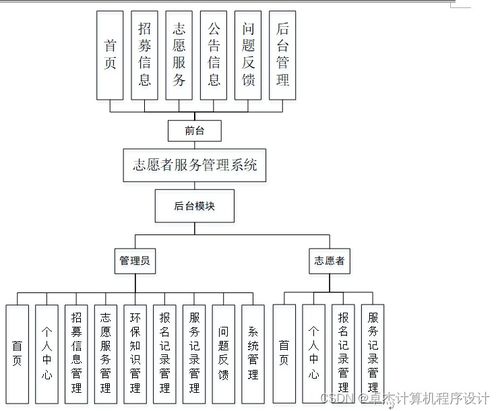
系統采用經典的分層架構,主要分為以下模塊:
- 數據采集與處理層:負責收集用戶行為日志(點擊、停留時長、評分)、新聞元數據(標題、分類、標簽、發布時間)。使用Flume、Kafka等工具進行日志采集,并利用Hadoop或Spark進行離線數據清洗與特征提取,為推薦算法準備高質量的數據集。
- 推薦引擎核心層:這是系統的“大腦”。它接收處理后的數據,運行協同過濾算法模型,定期(如每日)更新用戶興趣模型和新聞相似度矩陣,并實時響應用戶的推薦請求。算法模塊可以設計為可插拔的,便于未來集成更復雜的深度學習模型。
- 業務應用層(SpringBoot后端):基于SpringBoot構建RESTful API,提供用戶注冊登錄、新聞瀏覽、行為上報、個性化推薦列表獲取、反饋收集(如喜歡/不喜歡)等功能。該層負責銜接前端與推薦引擎,處理業務邏輯。
- 數據存儲層:采用混合存儲策略。用戶信息、新聞元數據等結構化數據存儲在MySQL中;用戶行為日志、大規模的相似度矩陣等則存儲在Redis(緩存熱數據)和HBase或MongoDB(存儲歷史與稀疏矩陣)中,以平衡性能與容量。
- 前端展示層:通常使用Vue.js或React等框架開發響應式Web界面,直觀展示新聞列表、推薦欄目及用戶個人中心。
4. 關鍵實現流程
- 用戶行為建模:系統持續記錄用戶的隱性反饋(如點擊、閱讀完成度)和顯性反饋(如評分、點贊)。這些數據是協同過濾算法訓練的燃料。
- 相似度計算與模型訓練:離線任務周期性地計算用戶-用戶相似度或新聞-新聞相似度,并生成推薦模型。SpringBoot可以集成調度框架(如Quartz)來管理這些定時任務。
- 實時推薦:當用戶訪問系統時,后端API根據其ID,從推薦模型中檢索出Top-N的新聞ID列表,再結合新聞熱度、時效性等因素進行加權排序,最終生成個性化的推薦列表返回給前端。
- 效果評估與優化:通過A/B測試,對比不同算法或參數下的點擊率、轉化率等指標,持續優化推薦效果。系統需預留評估接口。
5. 項目特色與挑戰應對
- 特色:系統充分結合了SpringBoot的工程化優勢和協同過濾算法的成熟性,實現了一個從數據到服務的完整閉環。模塊化設計使得算法部分易于迭代升級。
- 挑戰與應對:
- 冷啟動問題:對于新用戶或新新聞,采用基于內容的推薦(分析新聞關鍵詞、分類)或熱門新聞推薦作為補充,待數據積累后再啟用協同過濾。
- 系統性能:利用Redis緩存熱門推薦結果和用戶會話信息,確保高并發下的響應速度。SpringBoot的內置Tomcat容器和微服務理念便于水平擴展。
- 可擴展性:通過將推薦引擎設計為獨立服務,可以方便地將其部署為Docker容器,并集成到更大的微服務生態中。
6. 與展望
本項目設計的基于SpringBoot和協同過濾的新聞推薦系統,為計算機系統服務提供了一個實踐性強的畢業設計范例。它不僅涵蓋了現代Web系統開發的主流技術棧,還深入應用了經典的數據挖掘算法。該系統可以進一步探索基于深度學習的混合推薦模型,引入實時流處理技術(如Flink)進行在線學習,并加強推薦結果的多樣性和可解釋性,從而向更智能、更人性化的推薦服務平臺演進。